Bot protection

Bot protection heavily relies on the infrastructure your website/web app uses. For example, the anti-bot solution will look very difficult on NGinx Web server, as opposed to Microsoft IIS. Further, you might find yourself with tied hands if you’re using a kind of SaaS solution (for example, a Shopify store will be able to use only anti-bot protection offered by Shopify itself).
External Solutions
- DNS-based solutions, which take over DNS resolution for your website, and perform IP checks while doing IP resolution.
- If they detect a suspicious IP, they might reject it straight away (usually resulting in HTTP error 403), or redirect the user to a Captcha page where he should prove that he is not a bot
- Such solutions typically keep a record of IPs known to be used by bots – and they apply it to all their clients
- Such solutions also make it possible for clients to blacklist or whitelist certain IPs (or IP ranges) for which they are certain that they are welcome (or not welcome) to visit their website
- JavaScript-based solutions that inject a piece of JavaScript code into your page’s HTML
- The purpose of this JavaScript is to determine the nature of your browser (not just based on the UserAgent supplied in the HTTP header). it tries to distinguish fingerprints of Chrome Drivers used by bots, based on tiny differences in their JavaScript capabilities). Again, suspicious visits might get rejected, or forwarded to a page with Captcha’s (which come in more and more creative flavors)
- A combination of the above 2 methods
In-app solutions
- These solutions analyze the behavior of the visitor on your website – and based on it, decide if it’s suspicions or not
- These solutions work very well for sites requiring users to log in before accessing the desired page. The fact that the user needs to authenticate himself makes the job of bot detection much easier
- However, they require custom development, since each of them needs to tie into the Web application they are protecting
- Some of the typical criteria for detecting bots in-app
- Detecting user accounts who login too often, from too many different IPs
- Detecting visits who spend too little time on one page, before making a request for the next one (this criterion can be applied even for users who have not logged in)
- Detecting user accounts that create a multitude of orders, but never pay for them (indicating fake orders, which are usually used to establish the stock status on the site monitored by the bot)
Web / App Server plugins
In this scenario, you would investigate if the Web/application server you’re using comes with plugins that are able to detect potential bots (usually based on the visitor’s IP and UserAgent, the URLs they access on your website, and the frequency of requests). Please note that a more advanced bot (and Price2Spy is one such bot will most likely be able to circumvent this kind of protection)
Bot Detection
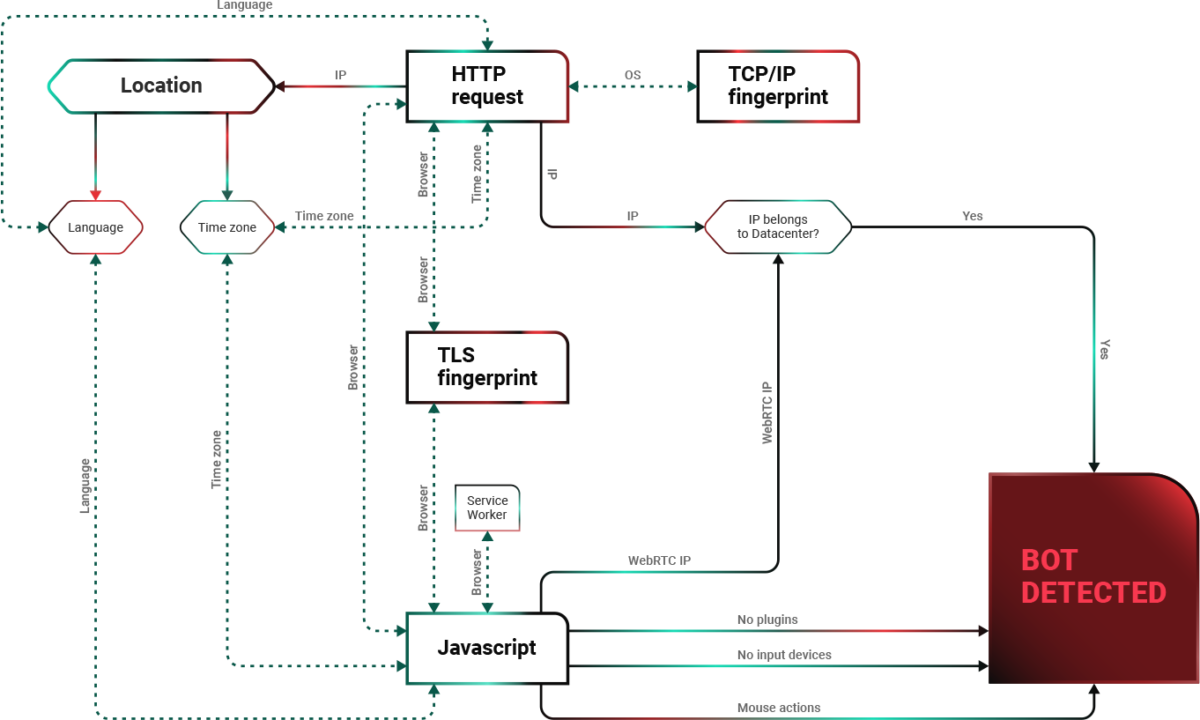
Risks of wrong bot detection

Just imagine that you visit an eCommerce site, because you consider purchasing a particular product – and the website shows a page explaining that it thinks you might be a bot, asking you to resolve a Captcha, which may consist of several pages of images showing cars, traffic lights, etc.
Annoying, isn’t it? So annoying, that you might drop the idea and go purchase the product on a different website.
This is the merchant’s nightmare – he fought for your visit very badly – and now he loses it because he wrongly detected you as a bot.
This illustrates how thin is the line of bot protection – it does need to stop the bots, but should never ever turn your clients away.
What to do when a bot gets detected
As discussed above, several approaches are possible
- Show ‘Access denied’ page – usually with 4xx HTTP response status page
- Show a Captcha, if you’re not positive it’s a bot
- Intentionally show wrong data. This is the most controversial course of action, very effective if successful, but potentially leading to disastrous effects if detection goes wrong.
- In Price2Spy, we monitor the websites of our client’s competitors, in order to capture the prices of their products. We have encountered certain sites, which – after determining that it’s a bot that’s visiting them – show the wrong price (either too high or too low) – in order to make the competitor, who is running the bot, get to the wrong business conclusion.